Introduzione al Machine Learning e applicazioni ad un problema di irrigazione
→
Europe/Rome
Description
![]()
![]()
Seminari IRSA-2022
Introduzione al Machine Learning e Applicazioni ad un problema di irrigazione
FABIO VITO DIFONZO
Università di Bari
https://sites.google.com/site/fabiovdifonzo/home
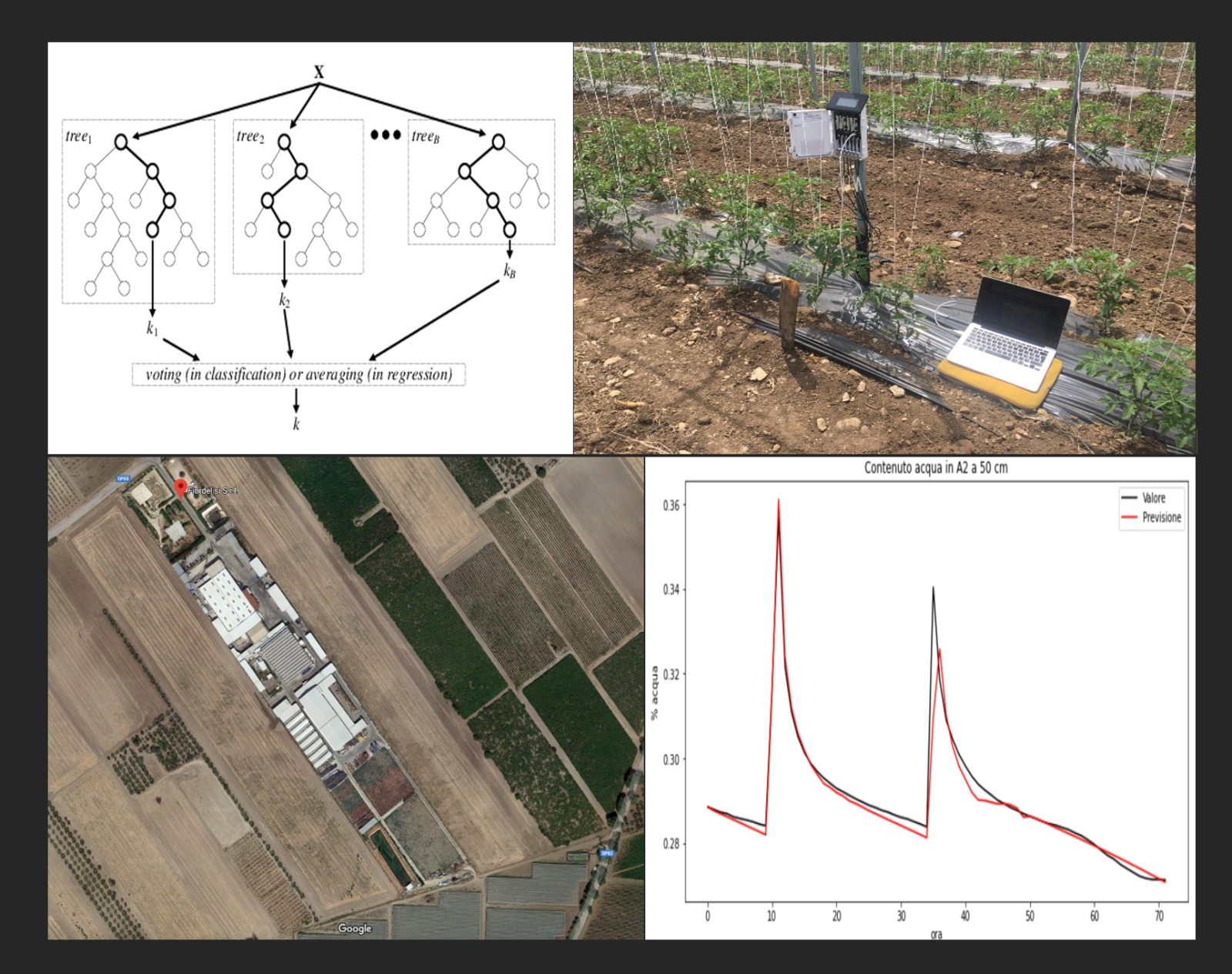
In questo seminario offriremo una semplice introduzione al Machine Learning (ML), un approccio che si riferisce al rilevamento automatizzato di modelli significativi in dati sperimentali, ampiamente utilizzato in applicazioni scientifiche come soil science, idrologia, agronomia ecc...
Presenteremo le principali caratteristiche di un modello ML, descrivendo come si strutturi, cosa significhi addestrare e testare un modello e come renderlo un potente e scalabile strumento di classificazione e predizione per classi estremamente ampie di problemi reali.
Mostreremo quindi un'applicazione significativa di modelli di previsione ad un problema di irrigazione. Specificamente, sulla base di dati meteorologici e di dati di irrigazione, di misure di contenuto d'acqua e salinità raccolti su un campo sperimentale a varie profondità del suolo, confronteremo differenti modelli ML per la previsione di queste due variabili, analizzandone i risultati.
Questi modelli si confermano decisamente promettenti per applicazioni in cui la ricchezza di dati consenta la creazione di strumenti ad hoc per pianificazione ed ottimizzazione di decisioni: essi possono essere competitivi rispetto a modelli fisicamente basati, con i quali possono essere anche integrati.
I partecipanti registrati riceveranno un link personale per connettersi mediante la piattaforma GoToMeeting.
Seminari IRSA-CNR